
Big Data & Analytics wird für Unternehmen aller Branchen zunehmend wichtiger. Die HMP konnte in Anbetracht der stetigen Zunahme von Big Data-Projekten das Know-Center in Graz als Kooperationspartner gewinnen. Das Know-Center ist eines der führenden europäischen Forschungszentren für Data-Driven Business und Artificial Intelligence. Diese Zusammenarbeit wird die Qualität und den Nutzen derartiger Projekte für die Kunden der HMP weiter erhöhen.
Die HMP und das Know-Center werden dabei die organisatorische, inhaltliche und technische Abwicklung von Projekten gemeinsam planen und durchführen. Die operativen Datenanalysen werden dann in der Infrastruktur-Umgebung des Know-Centers durchgeführt. Dort steht ein Hadoop-Cluster zur Verfügung, der nicht nur modernsten Anforderungen zur Verarbeitung großer Datenmengen, sondern auch alle relevanten Sicherheitsanforderungen in Bezug auf den Umgang mit sensiblen Daten gerecht wird. Eines der ersten gemeinsamen Projekte der beiden Kooperationspartner war ein Auftrag von Wiener Wohnen.
Ausgangslage: Konsolidierung und Vereinheitlichung der Daten
Der Konzern Wiener Wohnen, bestehend aus den Unternehmen Wiener Wohnen, Wiener Wohnen Kundenservice und Wiener Wohnen Hausbetreuung, hatte seit der Gründung heterogen verteilte IT-Architekturen und dadurch auch verteilte, datenhaltende Schlüsselapplikationen. Diese Architekturen sind teilweise durch Schnittstellen und Exportmechanismen zum gegenseitigen Austausch von Daten miteinander verbunden, jedoch wurde eine durchgängige Synchronisierung und Aktualisierung der Daten nie vollständig realisiert. Dies führt im Geschäftsbetrieb unter anderem dazu, dass die Aktualität der gespeicherten Informationen nicht immer gesichert ist und abweichende Datenstände existieren.
Im Zuge der Digitalisierungsoffensive des Konzerns ist es nun das Ziel, die Konsolidierung, Vereinheitlichung und Qualitätssicherung der Datensätze sicherzustellen, um damit das Fundament für zukünftige Digitalisierungsvorhaben zu schaffen. Als einen der ersten Schritte zur Erreichung dieser Vorgabe benötigte es dafür eine fokussierte Analyse der Datenbestände, um daraus die Handlungsempfehlungen und Konzepte für die Aggregation und Konsolidierung der Datenquellen des Konzerns zu entwickeln. Diese Aufgabe war der Kern des ersten gemeinsamen Projektes von HMP und Know-Center.
Umsetzung via CRISP-DM
Die im Projekt angewandte Methodik orientiert sich am branchenübergreifenden Prozess-Modell CRISP-DM (CRoss Industry Standard Process for Data Mining).
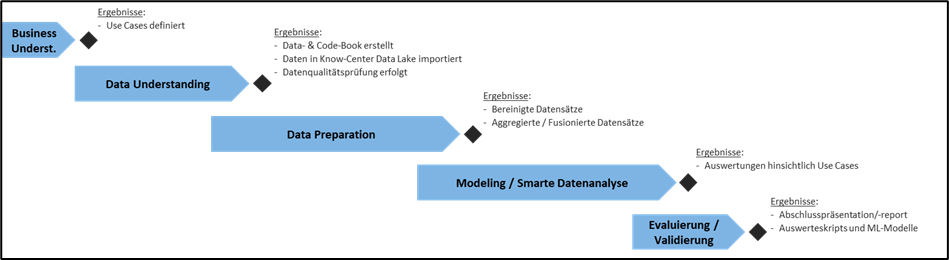
In der Phase des Business Understanding ging es vorwiegend darum zu verstehen, wie die vorliegenden Daten in Hinblick auf das geschäftliche Verständnis interpretiert werden müssen. Es wurden dabei die Fragestellungen bzw. Use Cases (Anwendungsfälle) für die weiterführenden Analysen herausgearbeitet, die DSVGO-Konformität sichergestellt und ein gemeinsames Verständnis zwischen Domain- und Datenexperten aufgebaut.
Das darauffolgende Data Understanding beinhaltete die Definition von aussagekräftigen Datenkategorien gemäß den erarbeiteten Fragestellungen. Diese Daten wurden in den „Data Lake“ (Apache Hadoop Cluster) des Know-Centers exportiert, einer Datenqualitätsprüfung unterzogen sowie das Data Book und das Code Book erstellt. Das Data-Book beinhaltete dabei Informationen zu den unterschiedlichen Datenquellen, welche im Projekt verwendet wurden. Es inkludierte Informationen wie die Quelle selbst, den Aufzeichnungszeitraum oder etwa Informationen zum Laden der Daten (z.B.: Encoding). Im Code-Book wurden alle Variablen detailliert gelistet und hinsichtlich ihrer Beschaffenheit und Qualität bewertet. Das Data- und das Code-Book bildeten die Grundlage für die weitere Datenverarbeitung.
In der nachfolgenden Phase der Data Preparation erfolgte schließlich die Vorverarbeitung, Bereinigung, Aggregation und Fusion der Daten. In dieser Phase wurden z.B. Ausreißer definiert, eine Dubletten-Erkennung durchgeführt und semantische Heterogenitäten entfernt. Die Phase Modelling/Smarte Datenanalyse beinhaltete erste Auswertungen hinsichtlich der Use Cases, Datenanalysen sowie weiterführende Empfehlungen basierend auf den Analyse-Ergebnissen.
Abschließend führte die Evaluierung/Validierung zu einer Präsentation der Ergebnisse und einem ausführlichen Abschlussreport. Dieser beinhaltet neben Tests und Empfehlungen für Optimierungen vor allem eine Übersicht hinsichtlich der notwendigen Konzeptionen zur Umsetzung in die IT-Architektur und in die Workflows von Wiener Wohnen insgesamt. Der Konzern verfügt damit nun über eine aussagekräftige Basis und über konkreten Handlungsempfehlungen, um in einem nächsten Schritt die detaillierte Konzeption und die Umsetzung eines vereinheitlichten Datenmanagements zu schaffen.
—
Link zum Know-Center – Research Center for Data-Driven Business &
Big Data Analytics